Ask, and You Shall Receive: Using Bert for Question-Answering with the World Happiness Report
Let’s see which country is the happiest country in the world according to Bert!
[Find the data and code for this article here.]
1. What is question-answering? How does it work?
QA is the task of extracting the answer from a given document. It needs the context, which is the document you want to search in and the question you want to ask, and it will return an answer to the given question.
QA task comes in many flavors such as extractive, open generative, and close generative, but the one we will focus on in this post is extractive question answering. This involves asking questions about a document and Bert identifying the answers as spans of text in the document itself. So, the answer is not generated but extracted from the texts.
The Start and End Token
There are three components in a QA generative task: The question, the context (your text/document), and the answer. Obviously, with an extractive QA, the answer is a part of the context.
Context: ‘Architecturally, the school has a Catholic character.
Atop the Main Building\’s gold dome is a golden statue of the Virgin Mary.
Immediately in front of the Main Building and facing it, is a copper statue
of Christ with arms upraised with the legend “Venite Ad Me Omnes”.
Next to the Main Building is the Basilica of the Sacred Heart.
Immediately behind the basilica is the Grotto, a Marian place of prayer
and reflection. It is a replica of the grotto at Lourdes, France
where the Virgin Mary reputedly appeared to Saint Bernadette
Soubirous in 1858. At the end of the main drive (and in a direct
line that connects through 3 statues and the Gold Dome),
is a simple, modern stone statue of Mary.’
Question: ‘To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?’
Answer: {‘text’: [‘Saint Bernadette Soubirous’], ‘answer_start’: [515]}
BERT needs to highlight a span of the context that contains the answer — that is basically represented by which token/word marks the start and which token marks the end of the answer. The start_position is the index of the token at the start of the answer, and theend_position is the index of the token where the answer ends. In the example below, the QA model was trained to predict the span for the answers by identifying the index of the token starting the answer (21) and the index of the token where the answer ends (24).

How does Bert’s QA model work?
- The process starts when every token in the text goes through the transformer encoder to turn each token into embedding — which is a fancy way of saying that we can represent text as an array of numbers. For every token in the text, we feed its final embedding into a question-answering linear layer which will output the start and end logits of each token.
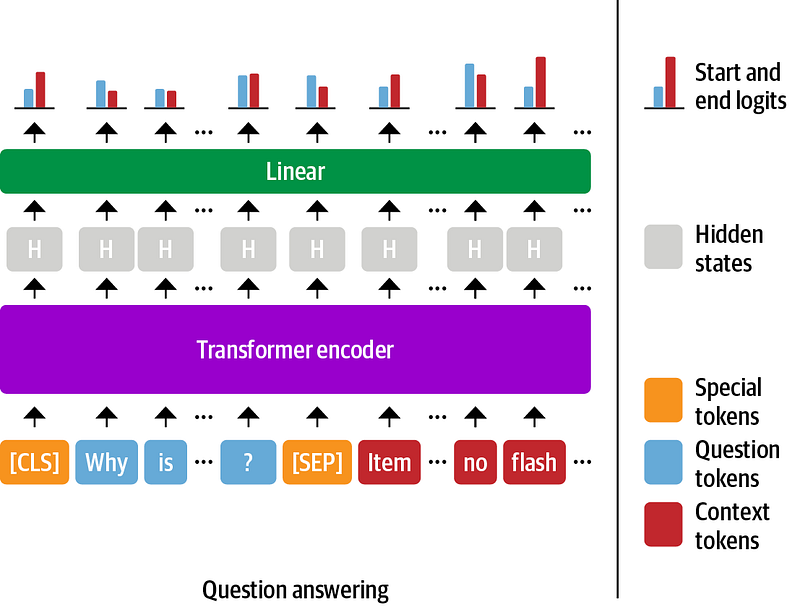
- Next, the start and end logits which correspond to tokens inside the question — so outside of the context will be masked. You want to mask them because you don’t want the answer to be the text in the question.
- We then converted the start and end logits into probabilities using a softmax function. Since we apply a softmax function, in order to mask a logit, we just need to replace the logits we want to mask with a large negative number, for example, -10000 and the softmax function will return the probabilities of almost 0 for this logit.
- Next, for each possible combination of start and end tokens, we calculate the probability that the answer starts at
start_indexand ends atend_index. Assuming the events “the answer starts atstart_index” and “the answer ends atend_index” to be independent, the probability is calculated as:
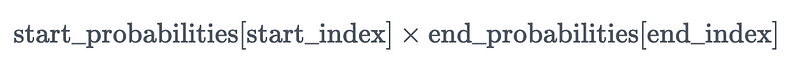
- For each combination of start and end tokens where the start_index ≤ end_index (because the start token should be before the end token), the QA model computes a score of each
(start_token, end_token)pair by taking the product of the corresponding two probabilities. - Finally, the pair with the maximum score will be the final answer.
Ok, enough theory! Let’s build the chatbot.
_Join the_** Medium membership** program to continue learning without limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
Join Medium with my referral link - Lan Chu
_Read every story from Lan Chu (and thousands of other writers on Medium). Your membership fee directly supports Lan Chu…_huonglanchu.medium.com
2. Building the Chatbot
We will be using an already fine-tuned BERT model from the Hugging Face Transformers library to answer questions.
Step 1. Prepare the data
First, let us prepare the data. For this exercise, we will use the WORLD HAPPINESS REPORT for the question-answering task in the form of a pdf file [1]. This is a landmark survey of the state of global happiness that ranks countries by how happy their citizens perceive/evaluate themselves to be. The WHR ranks countries not only by their welfare but also by their citizen’s subjective well-being and digs more deeply into how social and governance factors affect our happiness.
The data preparation is rather simple. First, let us create a function to extract the text from the pdf file and put them into a data frame.
def extract_text_from_pdfs(pdf_files):
"””
function to open and extract texts from pdf(s) document
"””
# Create an empty data frame
df = pd.DataFrame(columns=[‘file’, ‘text’])
# Iterate over the PDF files
for pdf_file in pdf_files:
# Open the PDF file
with open(pdf_file, ‘rb’) as f:
# Create a PDF reader object
pdf_reader = PyPDF2.PdfReader(f)
# Get the number of pages in the PDF
num_pages = len(pdf_reader.pages)
# Initialize a string to store the text from the PDF
text = "”
# Iterate over all the pages
for page_num in range(num_pages):
# Get the page object
page = pdf_reader.pages[page_num]
# Extract the text from the page
page_text = page.extract_text()
# Add the page text to the overall text
text += page_text
# Add the file name and the text to the data frame
df = df.append({‘file’: pdf_file.name, ‘text’: text}, ignore_index=True)
# Return the data frame
return df
Next, we will split the text into sentences by using common characters “.” and replace ‘/n’ with a white space that indicates a new line.
df[‘sentences’] = df[‘text’].apply(lambda long_str: long_str.replace("\n”, " “).split(”."))
I have also decided to remove short sentences — when sentences contain less than 10 words because they are usually the title of sections, and they may have perfect matching with my search query but sadly do not provide any answer to my question.
def preprocess_text(text_list):
# Initialize a empty list to store the pre-processed text
processed_text = []
# Iterate over the text in the list
for text in text_list:
num_words = len(text.split(” “))
if num_words > 10: # only include sentences with length >10
processed_text.append(text)
# Return the pre-processed text
return processed_text
def remove_short_sentences(df):
df[‘sentences’] = df[‘sentences’].apply(preprocess_text)
return df
Step 2. Use Semantic search to find the most relevant sentences to a query
The goal of using the semantic search here is to limit the search space for the QA model by identifying the most relevant sentences in the document given a particular search query.
The idea behind semantic search is to embed all the texts in your document, whether they are sentences, paragraphs, or words, into a vector space. Semantic search aims to improve search accuracy by understanding the meaning behind the search query. Instead of only finding documents based on matching words/lexical matches, semantic search can also find related terms and synonyms that may be relevant to the search.
These semantic search techniques turn texts into embeddings — a vector of a bunch of numbers. At search time, the query is embedded into the same vector space, and the closest embeddings (e.g., sentences from your document) to the embeddings of the query will be identified by comparing e.g., cosine-similarity, which uses the angle between two vectors to see how close they are. The higher the cosine similarity score (which means a smaller angle), the higher the semantic overlap to the query and hence, the closer the meanings.
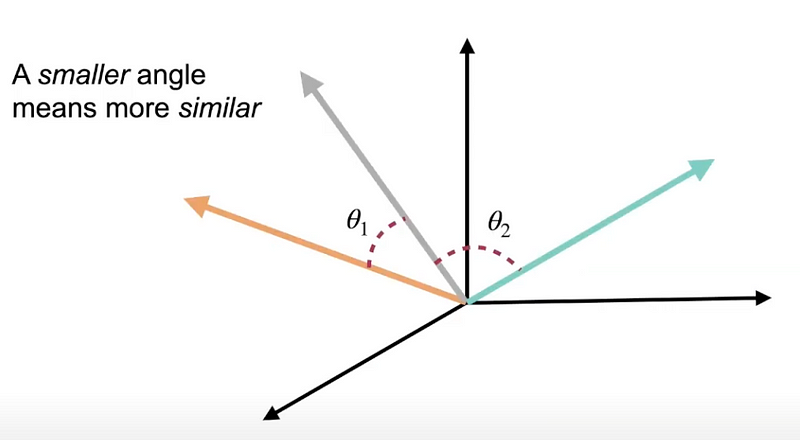
Transformers like Bert will return one embedding per token. So, for example, a Bert model will produce 9 embedding vectors for a sentence that has 9 words, and each vector has 384 dimensions. But what we really want is a single vector per sentence. To deal with this, you can use a technique called pooling on top of the contextualized word embeddings (see here for details). However, I will use SentenceTransformers, a framework for text and image embeddings that already takes care of sentence embeddings.
"””
We have a corpus with various sentences. Then, for a given search query,
we want to find the most similar sentence in the document.
This script outputs the similarity score for all sentences in the document.
"””
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(‘all-MiniLM-L6-v2’)
from sklearn.metrics.pairwise import cosine_similarity
cosine_threshold = 0.3 # set threshold for cosine similarity value
queries = [‘country ranking of happiness’] #search query
print("\nSemantic Search Results”)
results = []
for i, document in enumerate(df[‘sentences’]):
sentence_embeddings = model.encode(document)
query_embedding = model.encode(queries)
for j, sentence_embedding in enumerate(sentence_embeddings):
distance = cosine_similarity(sentence_embedding.reshape((1,-1)), query_embedding.reshape((1,-1)))[0][0]
sentence = df\['sentences'\].iloc\[i\]\[j\]
results += \[(i, sentence, distance)\]
results = sorted(results, key=lambda x: x[2], reverse=True)source: https://www.sbert.net/examples/applications/semantic-search/README.html
print(f"Query: {queries}")
print(f"Order by most relevant sentences in corpus:\n”)
for idx, sentence, distance in results:
if (distance > cosine_threshold):
print(f”{sentence.strip()}, \n{df[‘file’].iloc[idx]}\nCosine Score: {distance:.4f})")
print('———————–')
df = df.append({‘file’: ‘WHR+22.pdf’, ‘query’: ‘country ranking of happiness’, ‘sentence’:sentence,
‘cosine_score’: (distance)}, ignore_index=True)
After using semantic search, I have a list of the sentences along with their cosine similarity score to a given search query. In the example below, my query is “country ranking of happiness”.

Finally, we extract only the sentences that have a cosine similarity score larger than a pre-set threshold — which are considered the relevant sentences given the query. This will be our final “context” to look for the answer to the question.
# extract all the sentences from results that have a cosine similarity score larger than the threshold
# and put in a list
texts = []
for idx, sentence, distance in results:
if distance > cosine_threshold:
text = sentence
texts.append(text)
#turn the list to string
final_text = “".join(texts)
3. Building the pipeline and asking a question
Now that we have our final context let us build the QA pipeline and ask a question. Like any other pipeline, we will start by loading the model and tokenizer. For this exercise, we will use a fine-tuned model for question-answering tasks that has been built by Deepset.AI. The model has been fine-tuned for the Q&A task on the SQuAD 2.0 dataset, as denoted by squad2 at the end of the model name.
#loading the model
from transformers import BertForQuestionAnswering, AutoTokenizer
modelname = ‘deepset/bert-base-cased-squad2’
model_qa = BertForQuestionAnswering.from_pretrained(modelname)
Next, we initialize the model tokenizer. Tokenizing a text is splitting it into words or subwords, which then are converted to a list of integers (token ids) through a look-up table/internal dictionary in Bert that contains every token and its corresponding token ids.
#initalizing the tokenizer
tokenizer = AutoTokenizer.from_pretrained(modelname)
tokenizer.tokenize(“In World Happiness Report,
we presented comparable rankings for three subjective well-being measures”)
# returned tokens
[‘In’,
‘World’,
‘Happiness’,
‘Report’,
‘,’,
‘we’,
‘presented’,
‘comparable’,
‘rankings’,
‘for’,
‘three’,
‘subjective’,
‘well’,
‘-’,
‘being’,
‘measures’]
Great, we are ready to call the QA pipeline and ask a question by using the pipeline() function in the Transformers library that connects a model with its preprocessing and postprocessing steps. This allows us to directly input texts and get an answer:
nlp = pipeline(‘question-answering’, model=model_qa, tokenizer=tokenizer)
context = final_text
nlp({
‘question’: ‘which country occupies the highest ranking in life evaluation?’,
‘context’: context
})
{‘score’: 0.9334819316864014,
‘start’: 17580,
‘end’: 17587,
‘answer’: ‘Finland’}
Voila! It seems to work (because Finland definitely occupies the top spot in the country’s happiness ranking )!! We have just built our very first Q&A transformer model! The actions taken here are just a small piece of a puzzle, and there are additional things you can consider, such as fine-tuning a model using your own labeled data which is specific to a particular field (e.g., law or finance) to improve the model’s understanding of that domain. To fine-tune a QA model, you can follow the instruction here on hugging face. As long as your own dataset contains a column for contexts, a column for questions, and a column for answers, you should be able to adapt the steps.
References:
[1] https://happiness-report.s3.amazonaws.com/2022/WHR+22.pdf
[2] Hugging face transformer course: https://huggingface.co/course/chapter6/3b
[3] NLP with transformers notebook for Question-Answering
Thanks for reading!
If you are keen on reading more of my writing but can’t choose which one, no worries, I have picked one for you:
Understanding Term-based Retrieval methods in Information Retrieval
_This article explains the intuition behind most common term-based retrieval methods such as BM25, TF-IDF, Query…_towardsdatascience.com
By Lan Chu on January 5, 2023.